拿数据库做调查——怎么验证数据质量?



 编者按:《调查报道信息核实手册》(Verification Handbook for Investigative Reporting)是一本有关网络搜索和调查技巧的新鲜实用指南,指导人们如何利用UGC(user-generated content, 即用户生产的内容)和开源信息进行网络搜索和调查。此手册由总部设于荷兰的GIJN成员“欧洲新闻中心”(European Journalism Centre)出版,共有10章,均可免费下载。以下是获得授权转载并编译的该书第5章,由调查记者Giannina Segnini编写。
编者按:《调查报道信息核实手册》(Verification Handbook for Investigative Reporting)是一本有关网络搜索和调查技巧的新鲜实用指南,指导人们如何利用UGC(user-generated content, 即用户生产的内容)和开源信息进行网络搜索和调查。此手册由总部设于荷兰的GIJN成员“欧洲新闻中心”(European Journalism Centre)出版,共有10章,均可免费下载。以下是获得授权转载并编译的该书第5章,由调查记者Giannina Segnini编写。
时至今日,记者们接触信息的渠道之多前所未有。现在世界上每天生成的数据有3 EB之多,相当于7亿5千万张DVD 的容量之和 (1EB = 1024TB = 1048576GB = 1073741824MB),而且这个数字每3年零4个月就能翻一番。今天全球数据产量是以YB来计算的(1YB相当于250万亿张DVD的容量,即1024*1024EB=1048576EB)当数据容量扩充到YB以上,人们就开始讨论该用什么新单位来测量容量了。
数据生产的容量升级,速度提升,让众多记者无所适从。他们中很多人还不习惯用大量的数据做研究、写新闻。但是利用好数据的渴望和迫切,以及目前可用的处理数据技术,不能动摇基本的准确性要求。为了汲取数据的全部价值,我们必须具备区分可疑信息和优质信息的能力,能在干扰信息中发现真正有价值的故事。
我做数据调查已经20年了,得到的重要经验之一就是数据会说谎——就像人会说谎一样,它说谎的几率甚至更高。毕竟,数据通常是由人创造和维护的。
数据代表了某一特定时刻发生的事实。那么,怎么核实一个数据组是否和现实相符呢?
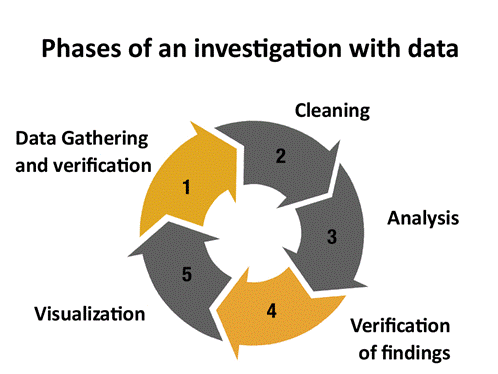
在数据驱动的调查中,我们有两大验证任务需要完成:一个是得到数据后必须马上做初步估算,再一个是当调查或分析阶段接近尾声时,必须要核实结果。
A. 初步验证
第一条就是对所有人和事物提出质疑。用数据一丝不苟地做新闻时,你会发现没有一个消息源是完全可靠的。
举个例子,你会完全信任世界银行发布的数据库吗?我问过的大多数记者都会回答“信任”;他们认为世界银行是可靠消息源。那就验证这判断对不对。我选了两个世界银行的数据组来说明如何验证数据,并向各位强调:甚至所谓“可靠”的消息源也有可能给出错误数据。我会沿下图所示的步骤带大家一探究竟:
1.数据完整吗?
我建议第一步先来探究数据集里每个变量的极值(最大值或者最小值),然后计算每个可能的数值里有多少记录(数据行)。
例如,1964年以来世界银行在全球有8600多个项目,它为此发布了一个数据库,收集了1万条项目独立评估。
在表格里升序排列“借出款项”这一数据,很快发现多条记录在这一列居然显示为零。

 这就意味着如果项目花费显示为零的条目得不到合理解释,任何人在计算或分析每个国家、区域,或年份时引用相关项目支出数据就可能出错。数据集就会导向错误结论。
这就意味着如果项目花费显示为零的条目得不到合理解释,任何人在计算或分析每个国家、区域,或年份时引用相关项目支出数据就可能出错。数据集就会导向错误结论。
世界银行发布了另一个数据库,涵盖了1947年以来它所资助的每个项目的单独数据(不仅仅是估算数据)。

在Excel里打开名为 api.csv 的文件(2014年12月7日的版本),你就会一目了然:数据混杂,一格里包含很多变量(例如领域名称或国家名称)。但更值得注意的是:文件并没有涵盖所有1947以来的投资项目。
实际上,数据库只收录了1947年以来世界银行15000多个项目中的6352个。(注:世银最终纠正了错误。到2015年2月12日为止,这份文件共收集16215条记录。)

只是稍微检查了数据,我们就发现世界银行的数据库并没有收录所有项目的支出。世界银行发布的数据杂乱,连一个涵盖所有项目的数据版本都没有 。那么,要是看上去不可靠的机构,你对它们发布的数据质量又能抱什么期望呢?
我在波多黎各开工作坊期间,发现了另一个数据库不一致的例子。 我们从审计官的办公室调用了政府合同数据库。去年全部的合同中,有72份政府合同在花费记录上出现了负值($–10,000,000)。
Open Refine是快速挖掘数据库、检测其质量的绝佳工具。下面第一张图中,你可以看到Open Refine可以用于运行 Cuantía (Amount)里一项名为“facet”的数字型字段(numeric)。numeric facet把数值分到相应的范围组中,你就能选择任何一个连续区间了。
第二张图显示的是你可以用数据库里的数值范围生成一个柱状图,在表格中移动箭头筛选数值。可用同样的方法筛选日期和文本数值。

2.是否有重复记录?
我们犯的一个普遍错误是处理数据时没辨识出重复记录。
处理涉及人、公司、活动或交易的分类数据或信息时,首先搜索每条信息的唯一识别项。以世界银行的项目评估数据库为例,每个项目都包含一个唯一编码,或者“项目ID”,以供识别。其他机构的数据库可能有唯一识别码,或者像政府合同数据库那样,有一个合同编码。
如果数清楚每个项目在数据库里有多少条记录,就能发现有些记录重复多达三次。因此,任何以每一个国家、区域或者日期为基础的计算,如果没有去除重复信息,就会出错。
 这种情况下,重复记录的产生是由于每一条记录都用了多重评估类型,我们必须选择最值得信赖的评估方式。(在这个例子中,“表现评估报告” [PARs]似乎是最可信的数据,它们让评估更有说服力。该数据独立评估小组(Independent Evaluation Group )所开发的,它每年独立、随机选取了世界银行25%的项目做抽样调查,派专家实地评估项目结果,发布独立评估报告。)
这种情况下,重复记录的产生是由于每一条记录都用了多重评估类型,我们必须选择最值得信赖的评估方式。(在这个例子中,“表现评估报告” [PARs]似乎是最可信的数据,它们让评估更有说服力。该数据独立评估小组(Independent Evaluation Group )所开发的,它每年独立、随机选取了世界银行25%的项目做抽样调查,派专家实地评估项目结果,发布独立评估报告。)
3. 数据准确吗?
确认数据表可信度的最佳方式之一,就是选择一条记录作为样本,将其和现实作比较。
世界银行的数据库按理应该收录了该机构所发起的所有项目,如果我们按每项花费的降序排列这些项目,会发现印度有一个项目花费最多,总额高达298.333亿美元 (相当于人民币1852亿元)。
如果我们在谷歌上搜索项目号(P144447),我们就能看到项目和其拨款的原版批准文件,清楚写着298.33亿美元的花费。这说明数字是准确的。
所以最好在记录中选取大量样本,一遍遍做数据验证练习。
 4. 核实数据的完整性
4. 核实数据的完整性
从第一次在电脑里输入数据,到获取数据,数据已经走过了输入、存储、传输和记录的过程。在每个阶段,它都可能遭遇人或者信息系统的篡改。
所以很普遍的一个现象是,数据表之间的关系,或者不同实际调查之间的关系,要么发生了偏离,要么混为一体,或者其中的一些变量没有更新。这就是为什么我们必须要做完整性测试。
例如,在世界银行的数据库里,还有不少多年前就得到批准的项目依然在“活跃”之列,即使很多项目已经结束了。
为了验证,我创建了一个数据透视表,把每年批准通过的项目分组。接着筛选数据,只显示那些在“状态”一列是“活跃”的项目。我们发现1986、87和89年审批通过的17个项目在数据库里依然显示为“活跃”。他们几乎都在非洲。


在此情况下,我们需要直接向世界银行求证,确认这些项目是否在近30年之后依然活跃。
我们应该使用其他的测试来检测世界银行数据的一致性。例如,检查贷款接收方(在数据库里显示的时“借款人”(borrowers))和(或)“国家名称”(Countryname)标注的国家组织与实际政府是否一一对应。或者看看这些国家分属的区域是否正确(查“区域名称”(regionname)一列)。
5. 破译编码和缩略词
吓跑记者的最好方法之一是给他/她充斥特殊编码和术语的复杂信息,这是希望隐瞒信息的官员和组织偏爱的伎俩。他们希望我们从公开信息里看不出个所以然。但编码和缩略词也有好处:可以减少用词量,扩充信息容量。几乎所有数据系统,不论公共还是私人,都用编码和缩略词来分类信息。
世界上很多人、机构和事物都有一个或数个专属编码。人们拥有身份证号、社保号码、银行客户编号,纳税人识别号,学号,雇员编号等。
例如,一把金属椅子在世界贸易里的编码是940179。每条船都有一个IMO编号(国际海事组织编号)。很多事物都有一条独有编码:房产、车辆、飞机、公司、计算机、智能手机、枪支、坦克、药物、离婚、婚姻……
因此我们必须学习如何破解编码,理解他们是怎么被用来表达数据库背后的逻辑,更重要的是,理解他们之间的关系。
全世界有1700万个货物集装箱,每一个都有一条唯一识别码,我们如果知道识别码开头的四个字母和物主的身份相关,就能依此追踪集装箱的去向。在这个数据库里,你可以查询物主信息。一条神秘编码的四个字母,就已经打开了获取更多信息的大门。
在世界银行记录评估项目的数据库里,编码和缩略词比比皆是,而令人惊奇的是,机构并没有发布统一的词汇表阐述编码的含义。一些缩略词甚至已经过时,仅在旧文件里出现。
例如在“资金调度工具(Lending Instrument)”这一栏,根据世界银行资助项目的16种信贷工具类型,把所有的项目分类:APL, DPL, DRL, ERL, FIL, LIL, NA, PRC, PSL, RIL, SAD, SAL, SIL, SIM, SSL 和TAL 。为了理解数据,有必要弄清楚这些缩略词的意思。否则你还不知道“ERL”指的是紧急贷款,专门贷给刚经历武装冲突或者自然灾害的国家。
编码SAD, SAL, SSL 和PSL和上世纪80、90年代世界银行争议颇多的“结构调整项目(Structural Adjustment Program)”有关。该项目贷款给身陷经济危机的国家,作为交换,这些国家调整经济政策,以削减财政赤字。(由于在好几个国家造成的社会影响,这个项目受到诸多质疑。)
世界银行称,自上世纪90年代末,他们更重视以“发展”为目标的贷款,而不那么重视那些旨在“调整”的了。但是,数据库显示,在2001年和2006年之间,150多笔批准的贷款标示的是“结构调整编码”。
这是数据库的错误?还是结构调整项目2000年之后仍在继续?
这个例子告诉我们:破解缩略词不仅是评估数据质量的极佳方式,更重要的是能发现公众关心的故事。
B. 在分析后核实数据
核实数据的最后一步的重点是发现和分析。这或许是验证过程中的最重要一步,也是验证故事或初步假设是否站得住脚的试金石。
2012年,我在哥斯达黎加媒体La Nación的跨领域团队任编辑。我们决定调查一项重要的政府公共补贴,名为“Avancemos”。这项补贴每月为公共学校的贫困学生提供助学金,让他们免于辍学。
在拿到资助学生信息数据库后,我们加上了他们父母的名字,然后对照查询哥斯达黎加的房地产、车辆、薪资和公司相关数据库。这样一来,我们就能列出一份完整家庭资产清单。(这是哥斯达黎加的公共数据,可以从最高选举法院获取)
我们假设:在16.7万受资助学生中,一些人的生活条件并不贫困,所以不应该接受每月补助。
在分析之前,我们确保完成对所有记录的鉴定、清理,也核实了每个人和其财产之间的联系。
其中一个发现是: 大约75名学生的父亲月收入超过2000美元(相当于12418元人民币,而非技术工的工资最低标准为500每月美元,相当于3105元人民币),1万多人拥有高价房产或车辆。
但实地探访他们家时,我们才知道数据背后的故事:这些孩子和母亲一同生活,的确贫困,因为他们的父亲已经抛弃了他们。
没人在发放教育资助之前询问过他们的父亲。结果,国家调用公共资金,资助了许多被不负责父亲抛弃的孩子。
这个故事浓缩了我在数据调查里学到的最有效的经验:即使最好的数据分析也不能代替现场新闻和实地核查。
 Giannina Segnini 是哥伦比亚大学新闻学院的访问学者。在2014年2月之前,她一直在哥斯达黎加的媒体La Nación领衔一支由记者和工程师组成的团队,致力于在收集、分析、可视化公共数据库的基础上做调查新闻。从2000年开始,她已培训了美洲、欧洲和亚洲的数百位记者。
Giannina Segnini 是哥伦比亚大学新闻学院的访问学者。在2014年2月之前,她一直在哥斯达黎加的媒体La Nación领衔一支由记者和工程师组成的团队,致力于在收集、分析、可视化公共数据库的基础上做调查新闻。从2000年开始,她已培训了美洲、欧洲和亚洲的数百位记者。

本作品采用 知识共享许可协议 署名-禁止演绎 4.0 国际 进行许可
您可以根据知识共享协议条款免费转载这篇文章
转载
This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License
阅读更多

深度报道精选
深度报道精选:被清仓的方舱医院、“妈妈岗”争议、“骂游戏”产业链
“清仓”取代“清零”,引发争议的“妈妈岗,“骂游戏”如何成为了一个产业链的关键一环……全球深度报道网精选了6月值得一读的深度报道。


深度报道方法
如何用 AI 工具助力开源调查?以识别模糊文本为例
无论是从短视频中提取重要信息,还是解码社交媒体配图中的模糊文字,Henk van Ess 在这篇文章中分享了如何用 AI 工具助力开源调查,以及如何建立一套审核证据的系统。

他们是如何做到的?
调查约会应用在保护女性上系统性失效,他们是如何做到的?
“约会应用报道项目”耗时18个月调查多个主流约会平台后发现,这些应用标榜的安全保护功能存在严重缺陷,无法有效保障用户,尤其是女性用户的安全。这个团队是如何进行调查的?