
图:Henk van Ess



你是否有过这样的感觉:当你盯着一份关键证据——一张模糊的车牌、一份像素化的文档,上面的名字你辨认不清,或是一张颗粒感的截图,你知道你需要的信息就在那里,却被一堵像素墙挡住,嘲弄着你?
你没有这种经历?那你可真幸运。我在调查中经常遇到这个问题——无论是从录像中提取姓名,解码社交媒体帖子中的部分数字,还是阅读文档中扭曲的文字。当其他人都在过自己的生活时,我却在玩“猜像素”的游戏。我并不介意。将不可读的信息转化为可读情报的能力简直太棒了。
现在是时候写一份让模糊不清的垃圾信息变得有意义的文章了。本文中的工具和技术并非理论性的。它们是你可以应用于自己难以辨认的证据的实用方法。因为在 OSINT 中,从死胡同到突破,往往就在于如何让那最后的几个像素发挥作用。
真正的工作发生在你的大脑和眼睛之间——知道如何组合工具,如何验证输出,以及何时信任(或不信任)你的结果。因为归根结底,业余时间和专业调查的区别在于拥有一套即使像素在反抗也能始终奏效的系统。
模糊的车牌
开源情报领域的人们热爱他们的工具。询问任何专家推荐,他们都会脱口而出诸如“直接用 Topaz Gigapixel Pro”或“试试任何基于陀螺仪的神经网络单幅图像去模糊工具——这里是所有这些工具的列表”之类的名字。但真正的解决方案并非总是在你最喜欢的软件中;它往往在于承认你并非无所不知。
在伦敦的一次会议上,我向 BBC Verify 的 50 个人展示了这张模糊的车牌。他们中的大多数人都能轻易地说出三种可以帮助去模糊化的工具。但问题是——它们都没有奏效。现在你有什么选择呢?

图:Henk van Ess
我在2025年最爱技巧是:我把我所有失败的尝试都输入到一个人工智能聊天机器人里,就像进行一场“数字疗法”一样——“我试过了 Topaz、Remini、DeblurGAN v2、ImageJ+ DeconvolutionLab2”——然后看着它建议“BeFunky Image Editor”。真的假的?我以前从未听说过 BeFunky,但事实证明,这个名字听起来像是被 Netflix 拒绝的原创作品的免费工具,在这种情况下竟然比我那200美元的昂贵软件效果更好。这简直是“也许我并非无所不知”精神的巅峰体现,说实话,真正的突破就是这样发生的:

图:Henk van Ess
那个工具之后就没那么好用了,但当我把它列在我已经尝试过的工具中时,我又得到了新的建议。有时候,最好的建议来自于分享你的失败经历。当你真的能读懂文本时,你需要找到上下文。在研究一辆红色雪佛兰科迈罗(一名荷兰罪犯使用)的车牌时,我读懂数字没遇到问题——我的问题在于反向图片搜索。有时候谷歌就是无法识别照片中被裁剪的细节。

Image: Courtesy of Henk van Ess
你可以通过在 Google 图片中输入可见文本来解决这个问题,而不是反向搜索照片本身。这让我找到了伊朗游客驾驶同一辆红色雪佛罗兰科迈罗和同一车牌的照片。啊,原来罪犯租了一辆车(完整故事在此)。
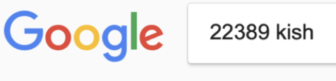

图:Henk van Ess
使用 AI
这里有一个听起来蠢到难以置信的专业技巧:如果你的文本质量不是完全“土豆画质”,那就直接让 AI 转录它。不需要花哨的工具,不需要图像处理的魔法——只要上传它,然后说:“这是什么?”我目前最喜欢的是 Gemini Pro 2.5,它显然已经决定成为世界上最“大材小用”的校对员了。
图:Henk van Ess
当你还在眯着眼试图分辨那是个“a”还是一个悲伤的表情时,聊天机器人已经为你转录并翻译了那段无法辨认的文字:

图:Henk van Ess
170 个难以辨认的词
你看看这张照片。我经常出差,所以不能随身携带显示器。相反,我用虚拟现实眼镜来完成工作。在这张我故意尽可能模糊的截图中,你能辨认出多少个词?
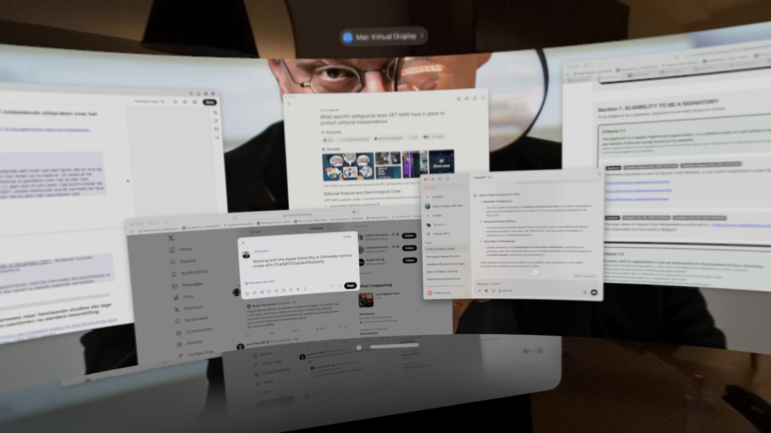
图:Henk van Ess
当你还在眯着眼睛看这张图片的时候,我已经把它上传到了 Gemini 2.5 Pro。它成功地从照片中识别出了大约 170 个词,并准确地总结了我当时正在做的事情。
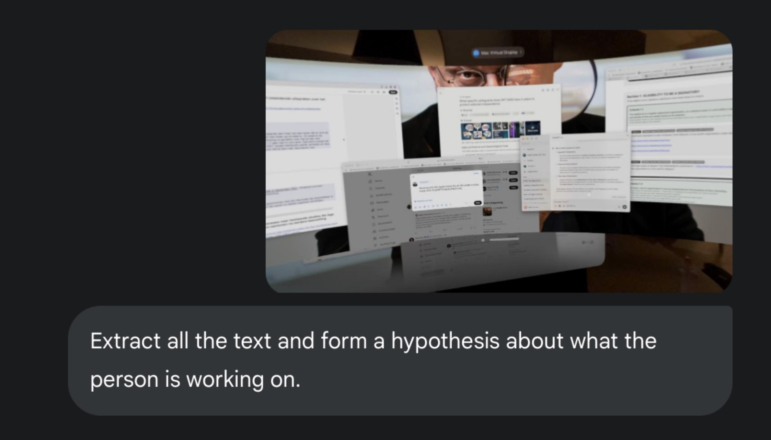

图:Henk van Ess
利用文本进行地理定位
我最近在柏林工作了两周,我喜欢给学生们做这些 OSINT(开源情报)的入门讲座,讲述调查技术可能有多么惊人的效果。它既有教育意义,又有点令人毛骨悚然,而且肯定会让每个人都立即检查他们的隐私设置。
我们来分析一下这张照片。问题是:这是哪里,是什么时候?

Image: Courtesy of Henk van Ess
“禁止自行车”的标志很可能排除了马耳他、塞浦路斯、西班牙、卢森堡和英国,而使得荷兰、丹麦和芬兰成为极有可能的候选国家。原因很简单:“禁止自行车”的标志最常见于自行车普及的国家。这些标志不太可能出现在根本没人骑自行车的地方——它们存在于骑自行车的人如此之多,以至于你需要积极地告诉他们不要把车停在这里的地方。这就像在海滩上找到“禁止游泳”的标志,而不是在撒哈拉沙漠中央找到一个——前者是实际的公共安全措施,后者只是海市蜃楼。你可以看到文字出现了两次——一个词是“essen”或以“Essen”结尾——还有一个带三到四个词的绿色标志。这一次,AI 没有胜过我们:
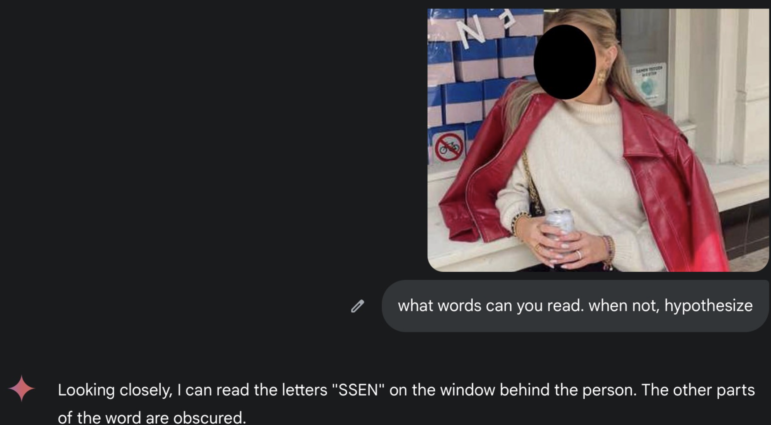
Image: Courtesy of Henk van Ess
BeFunky 能再次发挥作用吗?它将文本质量改善到我能识别出“samen redden”的程度。这意味着文本是荷兰语,意思是“samen redden [something]”——翻译过来就是“一起拯救 [something]”。

Image: Courtesy of Henk van Ess
那么,什么值得拯救呢?这可能是一个商店或餐馆橱窗上的贴纸,所以它可能不会说“一起拯救……共产主义”。也许它说的是:“一起拯救资本主义”?
不,别想了——那太牵强了。它可能是一些积极向上的东西,比如“一起拯救……能源”或“一起拯救……鲸鱼”,或者仅仅是“一起拯救……停车费”。或者……等等,不,我又在过度思考了。不要思考。停止猜测。开始搜索。
我们很确定“一起拯救”后面跟着一两个词——如果字体大小与第一行匹配,可能不超过七个字符。现在有趣的部分来了:你到底要如何向谷歌解释这种基于字体分析的、极其具体的字数估计,而又不让自己听起来像个喝了太多咖啡的阴谋论者?这就是普通搜索查询与法证排版(我们将在本文第二部分讨论)相遇的地方,每个人都会开始质疑你的人生选择。
你如何告诉谷歌你不知道正确的词?
用星号代替未知部分:

图:Henk van Ess
为什么要用引号?因为如果没有引号,谷歌会认为你指的是任何地方的“samen”和“redden”,而你实际需要这些词以确切的顺序放在一起。引号会强制谷歌将这些词作为一个实际的短语来查找,而不是像语言五彩纸屑一样散落在不同的段落中。最关键的是,当你结尾添加星号时,你是在告诉谷歌:
“这些词肯定会继续——后面还有更多文本,不要向我显示句子就此结束的结果。”
这基本上是在说:“不,我确实指的是这两个词挨在一起,而且我知道后面还有更多内容。”结果是:

图:Henk van Ess
原来是“一起拯救食物”——这来自 Too Good to Go 应用程序。在我们研究这个新事实之前,我们为什么要使用 Google 图片?当常规谷歌试图以其自然语言处理变得复杂时,Google 图片则像是在说:“哦,你想要图片中的文本?我有数百万张,我会准确地向你展示这些词共同出现的地方,包括你甚至不知道它们存在的地方。”
这就像是向图书馆员要关于“一起拯救食物”的书,和要求他们展示所有包含这些确切文字的照片之间的区别。前者会给你文章和评论,后者则会展示实际的店面和宣传海报。就像这个很棒的新工具,它能显示纽约 StreetView 中的所有文本:

图:Henk van Ess
回到我们的案例。Too Good to Go 基本上就是蔬菜和隔夜糕点的交友应用程序,餐馆、超市和咖啡馆会在最后一刻把他们未售出的食物放上去,供人们“拯救”。

图:Henk van Ess
是时候调查那些“SSEN”字母了。下一站:Claude,语义分析器。
我给它提供了具体信息——荷兰语单词以“essen”结尾,出现在餐馆或商店橱窗上——它立即回复了“Delicatessen”(熟食店)。当然。当我还在玩侦探游戏时,实际的解决方案就是询问一个专门处理语言模式的 AI。
图:Henk van Ess
有时最简单的方法就是承认你需要一个比你自己更好的大脑,尤其是一个真正懂荷兰语词汇的大脑。
我下载了 Too Good to Go 应用程序,并搜索了熟食店。我并没有感到惊喜。Claude 解释了原因:
图:Henk van Ess
是一个非常常见的后缀,所以列表会很长。例如,你可以有“Kaasdelicatessen”(奶酪熟食店)或“Chocoladedelicatessen”(巧克力熟食店)。多数列表都在阿姆斯特丹,所以我从那里开始。窗户后面似乎有白色和蓝色的盒子。

图:Henk van Ess
大这里有一个没人告诉你的有趣小技巧——如果你的调查依赖于特定的颜色,只需将它们附加到你的 Google 图片搜索的末尾,就像某种数字化的事后补充。

图:Henk van Ess
这就像给你的冰淇淋加糖屑,只不过糖屑是法证证据,冰淇淋是谷歌搜索。Delicatessen Amsterdam white blue 突然变成了一个极其具体的查询,它能过滤掉所有普通的餐馆列表,直接把你带到那些窗户上有奇怪特定颜色盒子的商店。谁知道颜色也可以成为搜索参数?这既是天才之举,又显而易见。

图:Henk van Ess
我们的第一个候选对象是阿姆斯特丹的 Flo’s Deli。

图:Henk van Ess
你猜怎么着,它第一次就完美匹配了。
我们这里得到的基本上就是 OSINT 领域的“第一次买彩票就中大奖”。看,左边是我们的起点——一个穿着红色夹克的神秘人物,坐在欧洲任何一家商店外面,他们的脸被好心地遮住了,因为显然隐私仍然很重要。我们能用来工作的只有“禁止自行车”的标志和一些模糊的颜色图案,这些图案可以是任何东西,从理发店的转灯到一张非常野心勃勃的井字棋盘。
右边展示了关键镜头:Flo’s Deli,上面有我们一直痴迷的“samen redden we eten”(我们一起拯救食物),一模一样的蓝白条纹窗户,以及那个“禁止自行车”的标志,就像一个骄傲的小灯塔一样说:“是的,这绝对就是这个地方!”
在不同的 AI 分析工具之间来回跳转,就像玩数字弹珠机一样——它们好心地确定,是的,这张照片可能是在春天或秋天拍摄的(感谢机器人带来如此开创性的季节性侦探工作)——我们用 OSINT 武器库中最美丽、经过时间考验的经典工具来结束这第一部分的“将无法辨认的文本转化为证据”:Google 地图中的时间机器。

图:Henk van Ess
2022 年 5 月,这家店还没有开业。所以时间范围一定在现在和 2022 年 5 月之间,对吗?

图:Henk van Ess
嗯,如果你有足够的时间——而且显然生活中没有更好的事情可做——你甚至可以通过查看成千上万张游客拍摄的商店照片,将其精确到更具体的时间段。因为这显然是一种完全正常的度过下午的方式。
那些白色和蓝色的盒子?它们装着百吉饼。

图:Henk van Ess
在调查突破的宏大图景中,这就像发现冰是冷的一样惊天动地。但有趣的是:通过查看其他上下文照片并追踪百吉饼展示的正常季节性起伏,你实际上可以将这张照片的时间精确到 2024 年秋季。
那么我们学到了什么?有时先进的法证技术意味着向 AI 聊天机器人寻求帮助,200 美元的工具可能会被一个叫做“BeFunky”的东西打败,而且分析阿姆斯特丹百吉饼的模式现在竟然是合法的侦探工作。
但真正的启示是:让无法辨认的文本变得可读的秘密不在于任何单一工具。它在于拥有一套系统——仔细审查每个细节,结合多种方法,在自己陷入困境时寻求帮助(即使帮助是来自 AI)。
编者按: 本文首次发表于 Henk van Ess 在 Substack 平台上的时事通讯 Digital Digging。全球深度报道网经授权翻译转载
 Henk van Ess 借助网络和人工智能,教授、讲授和撰写关于开源情报的文章。这位资深客座讲师和培训师环游世界,举办互联网研究研讨会。他的项目包括 Digital Digging(AI 与研究)、Fact-Checking the Web,、Handbook Datajournalism(免费下载),并担任社交媒体和网络研究专家。
Henk van Ess 借助网络和人工智能,教授、讲授和撰写关于开源情报的文章。这位资深客座讲师和培训师环游世界,举办互联网研究研讨会。他的项目包括 Digital Digging(AI 与研究)、Fact-Checking the Web,、Handbook Datajournalism(免费下载),并担任社交媒体和网络研究专家。

本作品采用 知识共享许可协议 署名-禁止演绎 4.0 国际 进行许可
您可以根据知识共享协议条款免费转载这篇文章
转载
This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License
阅读更多

他们是如何做到的? 深度报道方法
揭露DOGE利用缺陷AI削减退伍军人关键服务,他们是如何做到的?
ProPublica最近一篇调查报道,通过泄露的文件以及对人工智能工具开发者的采访,揭示了特朗普政府在削减退伍军人医疗开支措施背后存在的大量错误。他们是如何一步一步完成这篇报道的?

报道工具和技巧 深度报道方法
新闻编辑室可以用 AI 聊天机器人做什么?
从菲律宾到英国,多家知名新闻机构已经推出了自己的 AI 聊天机器人,它们可以根据该新闻机构过往的报道和经过严格审核的数据库来生成回应。

深度报道方法
人工智能时代,我们需要真正的新闻
随着人工智能技术的发展,许多新闻从业者害怕自己将被机器取代的声音也逐渐出现。然而,与其惊惧变化,不如拥抱这项技术。这篇文章给我们展示了,人工智能将可能如何帮助记者更好地报道我们如今所处的,愈发复杂、愈来愈全球化和信息过剩的世界,从而拯救新闻业。
