
圖:Shutterstock


將“美國轟炸伊朗對全球油價有何影響?”這類問題拋給主流的人工智能(AI)聊天機器人或搜索引擎,你會得到一連串看似確鑿的數據、網站鏈接和趨勢分析。例如,ChatGPT給出的長篇回答會這樣開頭:“布倫特原油價格一度飆升超過3%,達到每桶81至82美元左右——創下一月以來的新高。”
但如果向新聞機構內部的AI聊天機器人——例如《華盛頓郵報》的“Ask The Post AI”——提出同樣的問題,你通常會得到一個提綱挈領式的回答。這個回答會更簡潔、更謹慎,並附上其引用的新聞報道縮略圖:“截至目前,油價出現波動,全球原油價格下跌約1%,但局勢仍不明朗。”
兩者最主要的區別在於答案信息來源的可信度。大型語言模型(LLM)AI聊天機器人會搜索幾乎整個互聯網,包括未經審查的信源。而近幾年來,從菲律賓到英國,多家主流新聞機構紛紛推出了內部的生成式AI聊天機器人。這些機器人旨在專門依據自家網站的報道和經過審核的信源數據庫來回答讀者提問,並通過嚴格的代碼“護欄”來防止外部的虛假信息或偏見滲入。
這類智能新聞交互工具的代表性產品包括:菲律賓新聞網站 Rappler 的 Rai、英國《金融時報》的 Ask FT、福布斯的 Adelaide以及《華盛頓郵報》的Ask The Post AI。
(值得注意的是:這類工具不同於《華爾街日報》、彭博社和雅虎新聞等媒體所推出的AI新聞摘要工具。後者並不回答讀者提問,而是通過生成報道的要點總結,來幫助忙碌的讀者節省時間。)
所有這些聊天機器人都自稱尚處於實驗階段,並且可能會出錯。部分原因在於,它們建立在大型語言模型(LLM)的數字基礎架構之上,而LLM向來以其偏見、錯誤和“幻覺”問題而聞名。
但鑒於普遍的網絡搜索中充斥着虛假信息、錯誤歸因、無來源觀點和偏見等問題,這些新聞聊天機器人有一個共同的崇高目標:為讀者提供值得信賴的信息——而由於讀者對這些媒體品牌懷有忠誠度,他們本就傾向於信任這些信息。其答案完全生成自新聞機構檔案庫中經過充分報道和編輯的文章。此外,儘管AI聊天機器人存在潛在缺陷,專家們仍審慎樂觀地認為,它們或許能為新聞機構提供一些解決方案,以增強讀者互動、觸及年輕受眾,甚至開闢潛在的訂閱變現渠道。
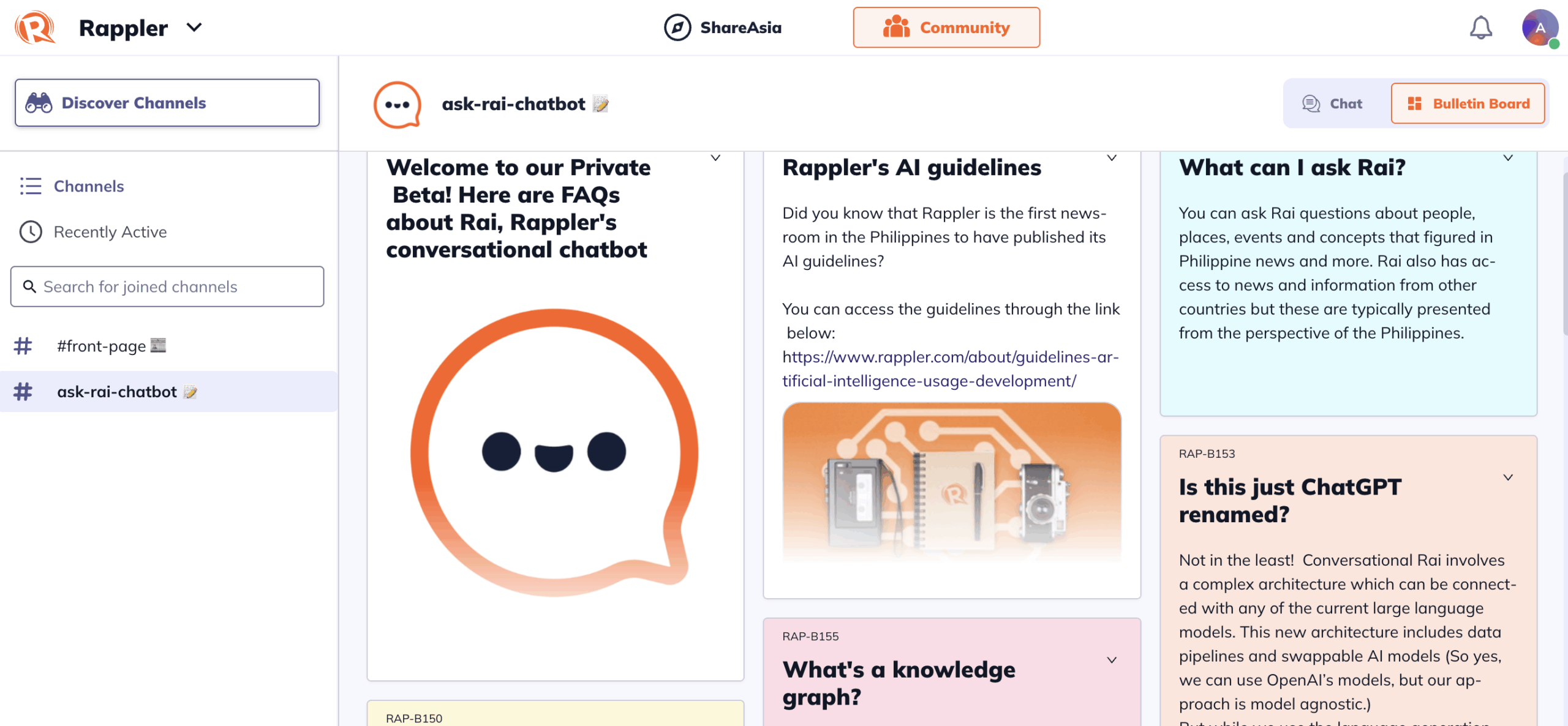
圖為 Rappler 的 Rai 界面
Rappler 新聞網的 Rai 最初是一項低風險的實驗:在Rappler聊天室這一相對安全的環境中,充當焦點小組討論的AI“主持人”。到了2024年10月,它在Rappler的應用程序上成長為一個更具雄心的工具:一個對話式機器人——而非摘要工具——其信息完全來源於Rappler發表過的四十多萬篇報道中的事實以及經過審核的數據集。據Rappler數字服務主管傑瑪·門多薩(Gemma Mendoza)介紹,這些資料包括Rappler自2011年成立以來發表的超過35萬篇文章,其前身《新聞內幕雜誌》(Newsbreak Magazine)十年間的深度報道和調查報道,以及菲律賓過去五次全國和地方選舉的結果、候選人和選民名冊等數據集。
門多薩表示,推出Rai的一個核心目的,是激勵讀者下載並使用Rappler的移動應用“Rappler社群”(Rappler Communities)。
她問道:“社交媒體確實已經降低了新聞的優先級,那麼你該如何與受眾互動?如何獲得可持續的流量,並讓受眾參與到你的內容中來?”她接著說:“另一種維持這種關係的方式是通過新聞信,但這在菲律賓並未真正成為一種習慣。我們為自己的應用設定了宏大的互動目標,而Rai正是一種能以更細緻入微的方式與用戶互動並呈現我們內容的方法。”
理論上,該系統背後的“知識圖譜”數據庫每15分鐘就會將最新的報道和調查文章加入其已歸檔的報道和信源數據資料庫中,然後Rai就能為應用用戶提供信息充分且相對及時的回復,並附上幾篇相關的報道鏈接。
門多薩說:“廣義上的人工智能存在一個問題,那就是它從四面八方獲取信息,並且基本上將每個信息點都等同視之。而在Rappler,我們為自己的報道負責,我們核查事實,而這正是Rai的根基所在。”
然而,新聞編輯室不像商業服務商那樣擁有龐大的數據工程團隊來維護這些複雜的系統,在新聞機構對話式機器人的這個實驗性時代,故障仍然很常見。例如,在7月的幾周里,由於更新功能出現問題,Rai未能收錄最新的報道,導致一些回答過時。
門多薩稱,儘管Rai建立在大型語言模型(LLM)的基礎架構之上,但其最新定製版本包含了創新且極其嚴格的“護欄”,以防止外部信息滲入到結果中。
正如該應用中的解釋說明所述:“這與其他聊天機器人不同,它們的數據來源包括各種隨機網站,其內容不一定經過審查。畢竟,垃圾進,垃圾出。”
她解釋道:“它確實是對話式的——我們在現有的LLM之上創建了一個基礎架構;這個架構是與平台無關的,所以如果需要,我們可以決定將其遷移到其他的LLM上。其回答均來源於已發表的報道和結構化數據。”
門多薩補充說:“我們專註於Rappler真正擅長的領域,首先從政治入手。”
聊天機器人的局限性
英國《金融時報》的生成式AI工具“Ask FT”僅對“FT專業版”訂閱用戶開放,其答案均來源於該報自2004年以來的歷史存檔。
今年五月,哥倫比亞大學新聞學院專業實踐教授比爾·格魯斯金(Bill Grueskin)對這款聊天機器人進行了測試。他指出,儘管其提供的事實都經過了新聞專業審核,但一些回答很快就暴露了其數據庫的局限性。他提到,“它似乎無法回答‘特斯拉在2024年賣了多少輛車?’這樣的問題。”
然而,儘管格魯斯金本人並非AI的常用者,他還是發現了這款聊天機器人的幾個優點。
“它的界面很簡單,”他說。“你只需在一個框里輸入問題——比如‘中美貿易戰的最新進展是什麼?’——幾秒鐘內,它就能生成一個周到、準確的摘要式回答,並附上腳註和為其提供信息的《金融時報》報道鏈接。”
在接受全球深度報道網採訪時,格魯斯金表示,新聞機構的AI模型在增強新聞互動、提升公眾知情水平以及改善存檔搜索方面,展現了適度的前景。

Ask FT pulls its answers from Financial Times archives dating back to 2004. Image: Shutterstock
“總的來說,我確實喜歡這個想法,”他解釋道。“原因之一是大多數新聞網站的搜索引擎都糟透了。即便是主流媒體的搜索功能也不盡人意:它們給出的結果很差,還不讓你按日期排序。相比之下,當我在谷歌中輸入關鍵詞,再加上‘site:nytimes.com’這樣的限定詞時,搜索結果要好得多。如果AI能改善這種體驗,並且答案都源自一個包含了已發表且經過編輯的報道的底層數據庫——這個數據庫還包括了記者後續所做的任何更正——那就太棒了。”
他補充道:“這一切的前提是,你得確保AI不會憑空捏造引語和事實。”
哈佛大學肯尼迪學院公共利益技術實驗室負責人拉坦婭·斯威尼(Latanya Sweeney)博士表示,除了數據庫有限之外,新聞機構聊天機器人還有一個潛在問題,即AI程序可能會根據過去的報道,無意中提供具有誤導性的答案。例如,關於某個政府部門的回答,可能會因為關於該話題的爭議性新聞報道中的事實而產生偏差。她說,一些新聞機構的交互工具最終可能會在單一新聞存檔的嚴格數據限制和由獨立新聞機構合作建立的更廣泛的互聯網存檔之間尋求一個中間地帶。
她解釋說:“如果你存檔中的文章在某個話題上非常狹隘,只談論了其中的一小部分,那麼它可能只會從那個角度來回答問題。但外界或許存在一個來源更可靠、更優質的答案。僅僅使用自己的存檔有很大的局限性。因此,如果能建立一個由可信新聞檔案組成的生態系統(來為AI提供答案),那或許會非常理想。”
專家表示,這些內部聊天機器人針對外部網站設置的數字防火牆極大地降低了它們捏造事實的風險,但並不能完全消除這種風險。
Rappler網站對Rai生成的回答採用其常規的編輯勘誤政策,並邀請讀者在聊天室或通過電子郵件指出任何可能的錯誤。該媒體聲明:“我們將努力找出錯誤根源,並在必要時更正源材料。”
對許多用戶來說,新聞機構聊天機器人最令人耳目一新、也最能建立信任感的特點之一,是它們有時會用一句“我不知道”來有效回應一個問題。如果你問《華盛頓郵報》的聊天機器人“1922年在倫敦下令暗殺亨利·威爾遜爵士的是誰?”,它會承認:“抱歉,我們無法生成答案。”但ChatGPT則會自信地回答:“很可能是由愛爾蘭自由邦臨時政府領導人邁克爾·柯林斯下令的,”儘管這一說法在一個引發了愛爾蘭內戰的事件上極具爭議和分歧。
門多薩提醒說:“AI的一個問題是,即使沒有經過審核的數據來回答,它也傾向於嘗試回答問題,所以必須設置好‘護欄’。因此,Rai懂得如何說‘我不知道這個’,這通常是因為它沒有把握能正確理解問題。”
在Rai發布時,Rappler的數據與創新主管唐·凱文·哈帕爾(Don Kevin Hapal)表示,該計劃為非營利新聞機構樹立了一個可以效仿的榜樣:“通過Rai,我們不只是推出了又一個AI工具,我們正在定義新聞編輯室應如何利用數據和AI來建立公眾信任。通過將Rai根植於Rappler嚴謹的新聞操守之上,我們證明了AI可以被負責任地整合,用以在虛假信息面前捍衛真相。”
在生成式AI出現之前,一些調查新聞機構曾基於交互式決策樹提供新聞問答界面。
一個突出的例子是智利的LaBot。在2017年至2023年間,用戶可以通過Telegram或Facebook Messenger,從記者預先寫好的一系列預期問題中進行選擇,通過點擊標籤頁找到關於該新聞機構自身報道的一系列對話式答案。
LaBot的聯合創始人弗朗西斯卡·斯科尼克(Francisca Skoknic)表示,那款實驗性聊天機器人的受歡迎程度說明了讀者普遍希望就事實進行簡短、可信的對話。
斯科尼克說:“我認為這些(新聞機構的AI)聊天機器人是有意義的,因為很多時候,人們沒有時間閱讀整篇文章,但確實想從一個值得信賴的品牌那裡獲得具體的答案——特別是如果這個媒體像Rappler一樣,擁有關於一個國家時事的全面、經審核的信息。但重要的是,這些工具必須能夠說‘我不知道’,而不是試圖強行給出答案。聊天機器人可以創造一種情感連接,這與閱讀新聞的感覺非常不同。”
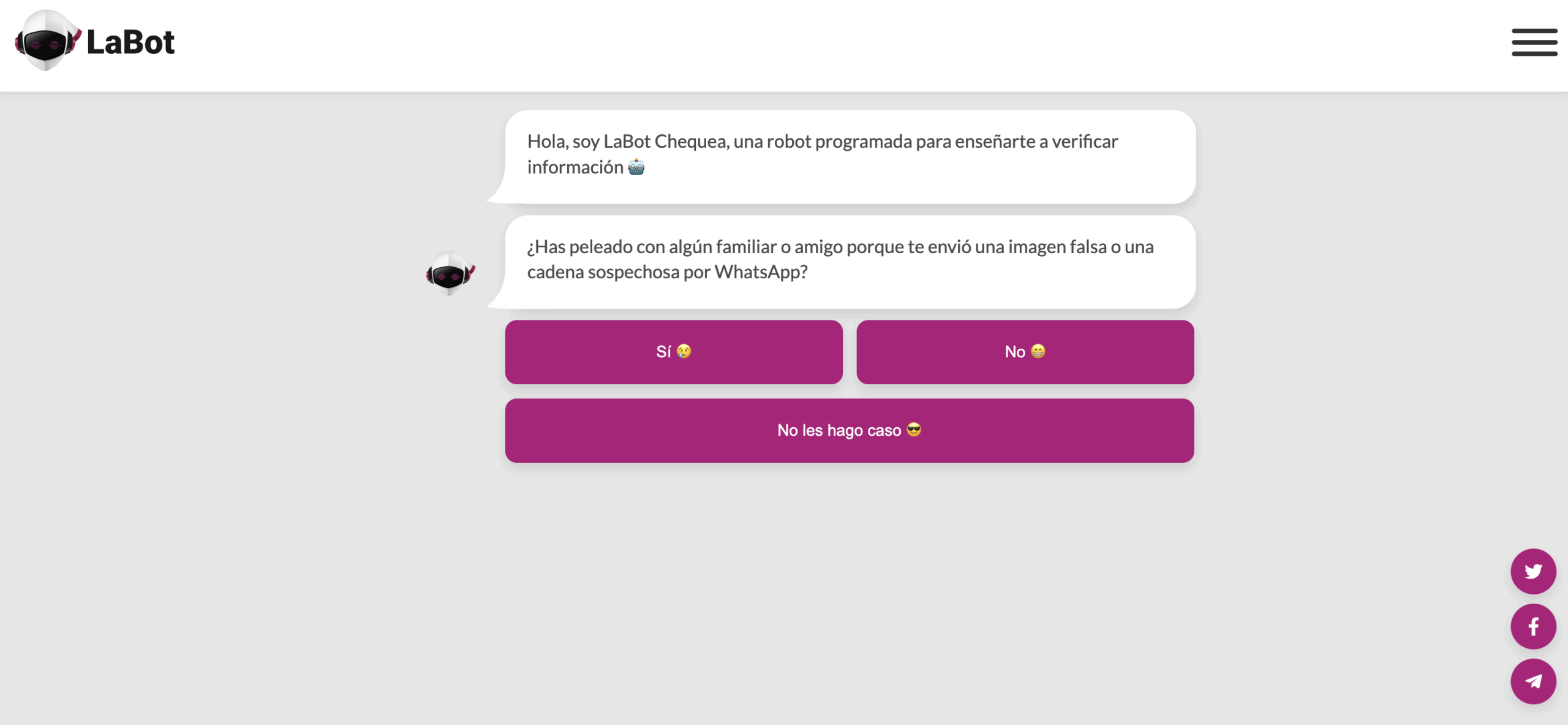
智利的 LaBot 界面
內部使用與開發
門多薩表示,這款聊天機器人也幫助了Rappler的記者準備新聞報道。
她指出:“我們的編輯團隊一直在大量使用它。例如,我們負責宗教事務的記者會自己為報道做基礎研究,但作為一種輔助手段,他會利用Rai幫助他梳理背景資料,整合Rappler已有的信息。”
她補充說:“Rai的一個用例是幫助你處理那些不常關注的議題。關於(前總統)杜特爾特的機密資金問題,已經舉行了多場馬拉松式的聽證會,你需要迅速跟上進度,這時你就可以向Rai詢問最新動態。‘關於健康保險基金的擔憂有哪些?’‘為什麼預算被削減了?’‘新聞里冒出來的這個人物是誰?’你都可以問Rai。”
對於其他考慮推出自有AI聊天機器人的新聞機構,門多薩警告說,讓記者深度參與到設計目標中至關重要。
她解釋道:“是的,你需要數據工程師和開發人員,並且要分階段部署這些工具。但重要的是,不能讓工程師單打獨鬥。你需要工程團隊和內容團隊之間的緊密結合。在這些機器人的工程設計中,你需要一種編輯思維。”
門多薩補充說,新聞機構應首先明確潛在聊天機器人的目的,並清晰地理解這項技術能做什麼、不能做什麼。
她解釋道:“摘要總結功能可以是即插即用的,但對話式聊天機器人並非如此。建立起‘護欄’架構非常重要,否則就有可能憑空捏造信息。”
 Rowan Philp 是全球深度報道網(GIJN)的全球記者和影響力編輯。他曾是南非《星期日泰晤士報》的首席記者,在全球二十多個國家報道新聞、政治、腐敗和衝突,並曾在英國、美國和非洲的新聞編輯室擔任派稿編輯。
Rowan Philp 是全球深度報道網(GIJN)的全球記者和影響力編輯。他曾是南非《星期日泰晤士報》的首席記者,在全球二十多個國家報道新聞、政治、腐敗和衝突,並曾在英國、美國和非洲的新聞編輯室擔任派稿編輯。

本作品採用 知識共享許可協議 署名-禁止演繹 4.0 國際 進行許可
您可以根據知識共享協議條款免費轉載這篇文章
轉載
This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License
閱讀更多

他們是如何做到的? 深度報道方法
揭露DOGE利用缺陷AI削減退伍軍人關鍵服務,他們是如何做到的?
ProPublica最近一篇調查報道,通過泄露的文件以及對人工智能工具開發者的採訪,揭示了特朗普政府在削減退伍軍人醫療開支措施背後存在的大量錯誤。他們是如何一步一步完成這篇報道的?

深度報道方法
如何用 AI 工具助力開源調查?以識別模糊文本為例
無論是從短視頻中提取重要信息,還是解碼社交媒體配圖中的模糊文字,Henk van Ess 在這篇文章中分享了如何用 AI 工具助力開源調查,以及如何建立一套審核證據的系統。

深度報道方法
人工智能時代,我們需要真正的新聞
隨着人工智能技術的發展,許多新聞從業者害怕自己將被機器取代的聲音也逐漸出現。然而,與其驚懼變化,不如擁抱這項技術。這篇文章給我們展示了,人工智能將可能如何幫助記者更好地報道我們如今所處的,愈發複雜、愈來愈全球化和信息過剩的世界,從而拯救新聞業。

深度報道精選
深度報道精選:毒紙尿褲事件、地下“捐卵”產業鏈、瀕危野生動物非法消費鏈
檢出甲酰胺的紙尿褲、瀕危野生動物非法消費鏈、中國的地下“捐卵”產業鏈……全球深度報道網精選了6月值得一讀的深度報道。