
圖:Henk van Ess


你是否有過這樣的感覺:當你盯着一份關鍵證據——一張模糊的車牌、一份像素化的文檔,上面的名字你辨認不清,或是一張顆粒感的截圖,你知道你需要的信息就在那裡,卻被一堵像素牆擋住,嘲弄着你?
你沒有這種經歷?那你可真幸運。我在調查中經常遇到這個問題——無論是從錄像中提取姓名,解碼社交媒體帖子中的部分數字,還是閱讀文檔中扭曲的文字。當其他人都在過自己的生活時,我卻在玩“猜像素”的遊戲。我並不介意。將不可讀的信息轉化為可讀情報的能力簡直太棒了。
現在是時候寫一份讓模糊不清的垃圾信息變得有意義的文章了。本文中的工具和技術並非理論性的。它們是你可以應用於自己難以辨認的證據的實用方法。因為在 OSINT 中,從死胡同到突破,往往就在於如何讓那最後的幾個像素髮揮作用。
真正的工作發生在你的大腦和眼睛之間——知道如何組合工具,如何驗證輸出,以及何時信任(或不信任)你的結果。因為歸根結底,業餘時間和專業調查的區別在於擁有一套即使像素在反抗也能始終奏效的系統。
模糊的車牌
開源情報領域的人們熱愛他們的工具。詢問任何專家推薦,他們都會脫口而出諸如“直接用 Topaz Gigapixel Pro”或“試試任何基於陀螺儀的神經網絡單幅圖像去模糊工具——這裡是所有這些工具的列表”之類的名字。但真正的解決方案並非總是在你最喜歡的軟件中;它往往在於承認你並非無所不知。
在倫敦的一次會議上,我向 BBC Verify 的 50 個人展示了這張模糊的車牌。他們中的大多數人都能輕易地說出三種可以幫助去模糊化的工具。但問題是——它們都沒有奏效。現在你有什麼選擇呢?

圖:Henk van Ess
我在2025年最愛技巧是:我把我所有失敗的嘗試都輸入到一個人工智能聊天機器人里,就像進行一場“數字療法”一樣——“我試過了 Topaz、Remini、DeblurGAN v2、ImageJ+ DeconvolutionLab2”——然後看着它建議“BeFunky Image Editor”。真的假的?我以前從未聽說過 BeFunky,但事實證明,這個名字聽起來像是被 Netflix 拒絕的原創作品的免費工具,在這種情況下竟然比我那200美元的昂貴軟件效果更好。這簡直是“也許我並非無所不知”精神的巔峰體現,說實話,真正的突破就是這樣發生的:

圖:Henk van Ess
那個工具之後就沒那麼好用了,但當我把它列在我已經嘗試過的工具中時,我又得到了新的建議。有時候,最好的建議來自於分享你的失敗經歷。當你真的能讀懂文本時,你需要找到上下文。在研究一輛紅色雪佛蘭科邁羅(一名荷蘭罪犯使用)的車牌時,我讀懂數字沒遇到問題——我的問題在於反向圖片搜索。有時候谷歌就是無法識別照片中被裁剪的細節。

Image: Courtesy of Henk van Ess
你可以通過在 Google 圖片中輸入可見文本來解決這個問題,而不是反向搜索照片本身。這讓我找到了伊朗遊客駕駛同一輛紅色雪佛羅蘭科邁羅和同一車牌的照片。啊,原來罪犯租了一輛車(完整故事在此)。
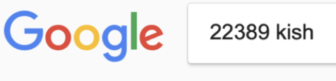

圖:Henk van Ess
使用 AI
這裡有一個聽起來蠢到難以置信的專業技巧:如果你的文本質量不是完全“土豆畫質”,那就直接讓 AI 轉錄它。不需要花哨的工具,不需要圖像處理的魔法——只要上傳它,然後說:“這是什麼?”我目前最喜歡的是 Gemini Pro 2.5,它顯然已經決定成為世界上最“大材小用”的校對員了。
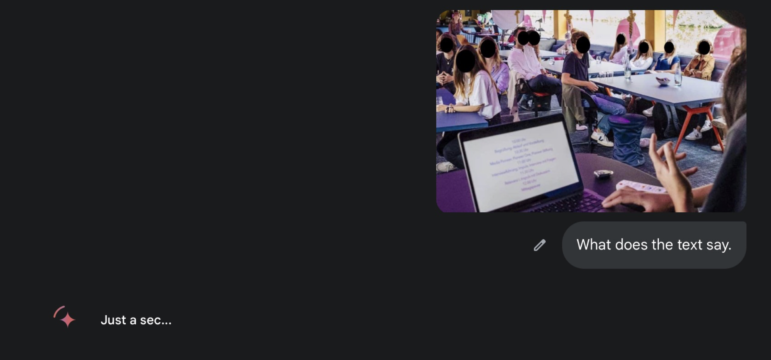
圖:Henk van Ess
當你還在眯着眼試圖分辨那是個“a”還是一個悲傷的表情時,聊天機器人已經為你轉錄並翻譯了那段無法辨認的文字:

圖:Henk van Ess
170 個難以辨認的詞
你看看這張照片。我經常出差,所以不能隨身攜帶顯示器。相反,我用虛擬現實眼鏡來完成工作。在這張我故意儘可能模糊的截圖中,你能辨認出多少個詞?
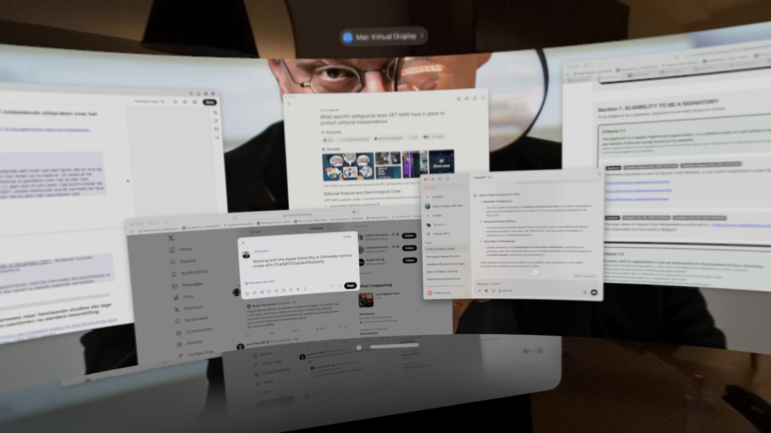
圖:Henk van Ess
當你還在眯着眼睛看這張圖片的時候,我已經把它上傳到了 Gemini 2.5 Pro。它成功地從照片中識別出了大約 170 個詞,並準確地總結了我當時正在做的事情。

圖:Henk van Ess
利用文本進行地理定位
我最近在柏林工作了兩周,我喜歡給學生們做這些 OSINT(開源情報)的入門講座,講述調查技術可能有多麼驚人的效果。它既有教育意義,又有點令人毛骨悚然,而且肯定會讓每個人都立即檢查他們的隱私設置。
我們來分析一下這張照片。問題是:這是哪裡,是什麼時候?

Image: Courtesy of Henk van Ess
“禁止自行車”的標誌很可能排除了馬耳他、塞浦路斯、西班牙、盧森堡和英國,而使得荷蘭、丹麥和芬蘭成為極有可能的候選國家。原因很簡單:“禁止自行車”的標誌最常見於自行車普及的國家。這些標誌不太可能出現在根本沒人騎自行車的地方——它們存在於騎自行車的人如此之多,以至於你需要積極地告訴他們不要把車停在這裡的地方。這就像在海灘上找到“禁止游泳”的標誌,而不是在撒哈拉沙漠中央找到一個——前者是實際的公共安全措施,後者只是海市蜃樓。你可以看到文字出現了兩次——一個詞是“essen”或以“Essen”結尾——還有一個帶三到四個詞的綠色標誌。這一次,AI 沒有勝過我們:
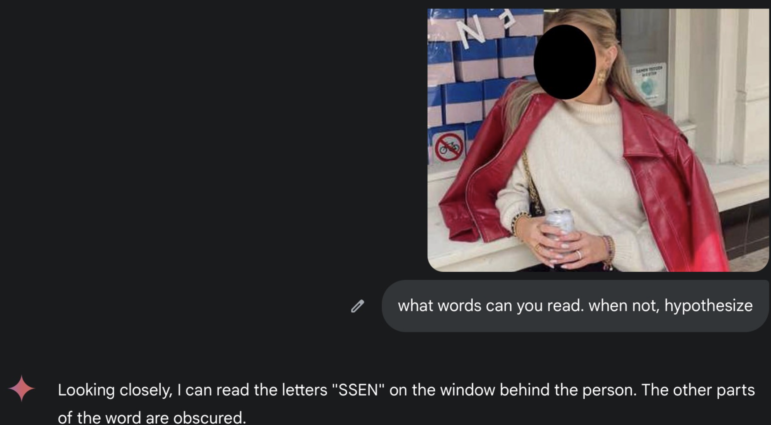
Image: Courtesy of Henk van Ess
BeFunky 能再次發揮作用嗎?它將文本質量改善到我能識別出“samen redden”的程度。這意味着文本是荷蘭語,意思是“samen redden [something]”——翻譯過來就是“一起拯救 [something]”。

Image: Courtesy of Henk van Ess
那麼,什麼值得拯救呢?這可能是一個商店或餐館櫥窗上的貼紙,所以它可能不會說“一起拯救……共產主義”。也許它說的是:“一起拯救資本主義”?
不,別想了——那太牽強了。它可能是一些積極向上的東西,比如“一起拯救……能源”或“一起拯救……鯨魚”,或者僅僅是“一起拯救……停車費”。或者……等等,不,我又在過度思考了。不要思考。停止猜測。開始搜索。
我們很確定“一起拯救”後面跟着一兩個詞——如果字體大小與第一行匹配,可能不超過七個字符。現在有趣的部分來了:你到底要如何向谷歌解釋這種基於字體分析的、極其具體的字數估計,而又不讓自己聽起來像個喝了太多咖啡的陰謀論者?這就是普通搜索查詢與法證排版(我們將在本文第二部分討論)相遇的地方,每個人都會開始質疑你的人生選擇。
你如何告訴谷歌你不知道正確的詞?
用星號代替未知部分:

圖:Henk van Ess
為什麼要用引號?因為如果沒有引號,谷歌會認為你指的是任何地方的“samen”和“redden”,而你實際需要這些詞以確切的順序放在一起。引號會強制谷歌將這些詞作為一個實際的短語來查找,而不是像語言五彩紙屑一樣散落在不同的段落中。最關鍵的是,當你結尾添加星號時,你是在告訴谷歌:
“這些詞肯定會繼續——後面還有更多文本,不要向我顯示句子就此結束的結果。”
這基本上是在說:“不,我確實指的是這兩個詞挨在一起,而且我知道後面還有更多內容。”結果是:

圖:Henk van Ess
原來是“一起拯救食物”——這來自 Too Good to Go 應用程序。在我們研究這個新事實之前,我們為什麼要使用 Google 圖片?當常規谷歌試圖以其自然語言處理變得複雜時,Google 圖片則像是在說:“哦,你想要圖片中的文本?我有數百萬張,我會準確地向你展示這些詞共同出現的地方,包括你甚至不知道它們存在的地方。”
這就像是向圖書館員要關於“一起拯救食物”的書,和要求他們展示所有包含這些確切文字的照片之間的區別。前者會給你文章和評論,後者則會展示實際的店面和宣傳海報。就像這個很棒的新工具,它能顯示紐約 StreetView 中的所有文本:

圖:Henk van Ess
回到我們的案例。Too Good to Go 基本上就是蔬菜和隔夜糕點的交友應用程序,餐館、超市和咖啡館會在最後一刻把他們未售出的食物放上去,供人們“拯救”。

圖:Henk van Ess
是時候調查那些“SSEN”字母了。下一站:Claude,語義分析器。
我給它提供了具體信息——荷蘭語單詞以“essen”結尾,出現在餐館或商店櫥窗上——它立即回復了“Delicatessen”(熟食店)。當然。當我還在玩偵探遊戲時,實際的解決方案就是詢問一個專門處理語言模式的 AI。
圖:Henk van Ess
有時最簡單的方法就是承認你需要一個比你自己更好的大腦,尤其是一個真正懂荷蘭語詞彙的大腦。
我下載了 Too Good to Go 應用程序,並搜索了熟食店。我並沒有感到驚喜。Claude 解釋了原因:
圖:Henk van Ess
是一個非常常見的後綴,所以列表會很長。例如,你可以有“Kaasdelicatessen”(奶酪熟食店)或“Chocoladedelicatessen”(巧克力熟食店)。多數列表都在阿姆斯特丹,所以我從那裡開始。窗戶後面似乎有白色和藍色的盒子。

圖:Henk van Ess
大這裡有一個沒人告訴你的有趣小技巧——如果你的調查依賴於特定的顏色,只需將它們附加到你的 Google 圖片搜索的末尾,就像某種數字化的事後補充。

圖:Henk van Ess
這就像給你的冰淇淋加糖屑,只不過糖屑是法證證據,冰淇淋是谷歌搜索。Delicatessen Amsterdam white blue 突然變成了一個極其具體的查詢,它能過濾掉所有普通的餐館列表,直接把你帶到那些窗戶上有奇怪特定顏色盒子的商店。誰知道顏色也可以成為搜索參數?這既是天才之舉,又顯而易見。

圖:Henk van Ess
我們的第一個候選對象是阿姆斯特丹的 Flo’s Deli。

圖:Henk van Ess
你猜怎麼著,它第一次就完美匹配了。
我們這裡得到的基本上就是 OSINT 領域的“第一次買彩票就中大獎”。看,左邊是我們的起點——一個穿着紅色夾克的神秘人物,坐在歐洲任何一家商店外面,他們的臉被好心地遮住了,因為顯然隱私仍然很重要。我們能用來工作的只有“禁止自行車”的標誌和一些模糊的顏色圖案,這些圖案可以是任何東西,從理髮店的轉燈到一張非常野心勃勃的井字棋盤。
右邊展示了關鍵鏡頭:Flo’s Deli,上面有我們一直痴迷的“samen redden we eten”(我們一起拯救食物),一模一樣的藍白條紋窗戶,以及那個“禁止自行車”的標誌,就像一個驕傲的小燈塔一樣說:“是的,這絕對就是這個地方!”
在不同的 AI 分析工具之間來回跳轉,就像玩數字彈珠機一樣——它們好心地確定,是的,這張照片可能是在春天或秋天拍攝的(感謝機器人帶來如此開創性的季節性偵探工作)——我們用 OSINT 武器庫中最美麗、經過時間考驗的經典工具來結束這第一部分的“將無法辨認的文本轉化為證據”:Google 地圖中的時間機器。

圖:Henk van Ess
2022 年 5 月,這家店還沒有開業。所以時間範圍一定在現在和 2022 年 5 月之間,對嗎?

圖:Henk van Ess
嗯,如果你有足夠的時間——而且顯然生活中沒有更好的事情可做——你甚至可以通過查看成千上萬張遊客拍攝的商店照片,將其精確到更具體的時間段。因為這顯然是一種完全正常的度過下午的方式。
那些白色和藍色的盒子?它們裝着百吉餅。

圖:Henk van Ess
在調查突破的宏大圖景中,這就像發現冰是冷的一樣驚天動地。但有趣的是:通過查看其他上下文照片並追蹤百吉餅展示的正常季節性起伏,你實際上可以將這張照片的時間精確到 2024 年秋季。
那麼我們學到了什麼?有時先進的法證技術意味着向 AI 聊天機器人尋求幫助,200 美元的工具可能會被一個叫做“BeFunky”的東西打敗,而且分析阿姆斯特丹百吉餅的模式現在竟然是合法的偵探工作。
但真正的啟示是:讓無法辨認的文本變得可讀的秘密不在於任何單一工具。它在於擁有一套系統——仔細審查每個細節,結合多種方法,在自己陷入困境時尋求幫助(即使幫助是來自 AI)。
編者按: 本文首次發表於 Henk van Ess 在 Substack 平台上的時事通訊 Digital Digging。全球深度報道網經授權翻譯轉載
 Henk van Ess 藉助網絡和人工智能,教授、講授和撰寫關於開源情報的文章。這位資深客座講師和培訓師環遊世界,舉辦互聯網研究研討會。他的項目包括 Digital Digging(AI 與研究)、Fact-Checking the Web,、Handbook Datajournalism(免費下載),並擔任社交媒體和網絡研究專家。
Henk van Ess 藉助網絡和人工智能,教授、講授和撰寫關於開源情報的文章。這位資深客座講師和培訓師環遊世界,舉辦互聯網研究研討會。他的項目包括 Digital Digging(AI 與研究)、Fact-Checking the Web,、Handbook Datajournalism(免費下載),並擔任社交媒體和網絡研究專家。

本作品採用 知識共享許可協議 署名-禁止演繹 4.0 國際 進行許可
您可以根據知識共享協議條款免費轉載這篇文章
轉載
This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License
閱讀更多

他們是如何做到的? 深度報道方法
揭露DOGE利用缺陷AI削減退伍軍人關鍵服務,他們是如何做到的?
ProPublica最近一篇調查報道,通過泄露的文件以及對人工智能工具開發者的採訪,揭示了特朗普政府在削減退伍軍人醫療開支措施背後存在的大量錯誤。他們是如何一步一步完成這篇報道的?

報道工具和技巧 深度報道方法
新聞編輯室可以用 AI 聊天機器人做什麼?
從菲律賓到英國,多家知名新聞機構已經推出了自己的 AI 聊天機器人,它們可以根據該新聞機構過往的報道和經過嚴格審核的數據庫來生成回應。

深度報道方法
人工智能時代,我們需要真正的新聞
隨着人工智能技術的發展,許多新聞從業者害怕自己將被機器取代的聲音也逐漸出現。然而,與其驚懼變化,不如擁抱這項技術。這篇文章給我們展示了,人工智能將可能如何幫助記者更好地報道我們如今所處的,愈發複雜、愈來愈全球化和信息過剩的世界,從而拯救新聞業。

深度報道精選
深度報道精選:毒紙尿褲事件、地下“捐卵”產業鏈、瀕危野生動物非法消費鏈
檢出甲酰胺的紙尿褲、瀕危野生動物非法消費鏈、中國的地下“捐卵”產業鏈……全球深度報道網精選了6月值得一讀的深度報道。